
Imagine deploying your applications in environments where resources are scarce, connectivity is unreliable, and every hardware decision counts. Whether it’s edge computing sites, remote data centers, or on-premises installations with limited infrastructure, ensuring high performance and availability can be challenging. OpenShift Compact Clusters emerge as a transformative solution tailored to address these exact scenarios, offering an efficient way to maximize resources while maintaining high availability and performance.
What are OpenShift Compact Clusters?
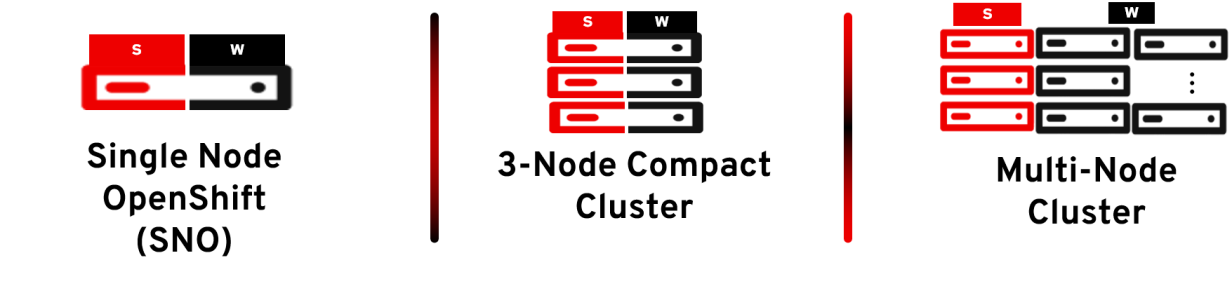
An OpenShift compact cluster is a streamlined deployment model where both control plane components and worker workloads coexist on the same set of nodes; specifically, three nodes. This means that services responsible for managing the cluster share resources with the applications running on the cluster. By consolidating these roles, compact clusters reduce the hardware footprint without sacrificing functionality or reliability.
1. Maximizing Efficiency and Reliability with Compact Clusters
OpenShift compact clusters are engineered for situations where resources are limited, but the demand for high performance and availability remains steadfast.
Key Insights:
- Consolidated Architecture: Think of a bustling co-working space where different teams share the same facilities efficiently. Similarly, OpenShift compact clusters have control plane components (like etcd, API servers, and schedulers) sharing nodes with application workloads. This setup reduces infrastructure overhead but requires meticulous resource management to ensure harmony between system services and user applications.
- High Availability (HA): Picture your cluster as a team of three strong pillars. If one falters, the other two keep everything steady. A three-node compact cluster ensures quorum is maintained even if one node goes down, preventing etcd from switching to read-only mode and keeping your cluster operational during failures and updates. Unlike Single Node OpenShift (SNO), where the entire cluster resides on a single node, making it susceptible to downtime during node failures or updates, a compact cluster offers enhanced resilience and continuous availability. This means you can perform rolling updates and maintenance without disrupting your workloads, a critical advantage in environments where uptime is paramount.
Best Practices:
- Dedicated NVMe for etcd: etcd acts as the brain of your cluster, requiring rapid data access to function optimally. By allocating high-speed NVMe storage exclusively for etcd, you ensure swift disk operations and reduce performance bottlenecks caused by shared disk resources. This dedication safeguards the ability of etcd to handle API requests efficiently, even under heavy load.
- Resource Planning for Control Plane Services: Balancing resources is akin to managing a tightrope walk. While dynamic scaling for control plane services like etcd isn’t feasible, it’s crucial to allocate sufficient resources to prevent these services from being starved by application workloads. Regular monitoring and adjustments help maintain stability, especially during peak demand periods.
- Optimized Network Setup: Imagine trying to have a conversation over a congested highway, communication breaks down. Similarly, network latency in compact clusters can hinder performance. Optimize your network with low-latency, high-reliability connections to ensure smooth communication between control plane components. Implement redundant networking setups to bolster stability in environments where network reliability is paramount.
2. Leveraging the Mirror Registry and the PinnedImageSet for Seamless Disconnected Deployments
In environments where internet connectivity is unpredictable, maintaining access to container images is crucial. OpenShift provides built-in solutions like the Mirror Registry and the new custom resource PinnedImageSet to ensure uninterrupted deployments, even in the most remote locations.
Update Approach:
Local Image Management with the Mirror Registry:
Think of the Mirror Registry as your on-site warehouse for container images. Included with OpenShift, the Mirror Registry allows organizations to host and manage container images locally, reducing reliance on external registries. This ensures that applications can be deployed seamlessly regardless of external connectivity issues.
Efficient Syncing with oc-mirror:
Using the oc-mirror CLI is like having a smart logistics system that only moves what’s necessary. oc-mirror syncs external container images and release payloads to your local registry incrementally, conserving bandwidth and keeping your local repository up to date without unnecessary data transfers.
Preventing Image Losses with the PinnedImageSet
In disconnected environments, there is a risk of image loss if a power outage occurs during image updates or if images are removed from external registries. The new PinnedImageSet custom resource addresses this challenge by ensuring that critical container images are preloaded and pinned on specific nodes within your cluster.
What Is the PinnedImageSet?
The PinnedImageSet is a custom resource in OpenShift that allows you to specify a list of container images to be cached locally on designated nodes. By preloading these images, you eliminate the need to pull them from external registries during deployments or restarts, ensuring they are always available when needed.
How Does It Work?
When you create a PinnedImageSet, you define:
- Node Selector: Specifies which nodes the images should be pinned to (e.g., control plane).
- Pinned Images: A list of image references (by digest) that you want to preload.
OpenShift then pulls these images and stores them locally on the specified nodes. This process ensures that even in the event of network disruption or power outages, your deployments won’t fail due to missing images.
Implementing the PinnedImageSet:
To utilize this feature, create a PinnedImageSet custom resource like the following example:
apiVersion: machineconfiguration.openshift.io/v1alpha1
kind: PinnedImageSet
metadata:
name: my-pinned-images
spec:
nodeSelector:
matchLabels:
node-role.kubernetes.io/control-plane: ""
pinnedImages:
- quay.io/openshift-release-dev/ocp-release@sha256:...
- quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:...
- quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:...
...
Code language: YAML (yaml)Why This Matters for Edge Environments:
- Operational Independence: Ensures that essential images are available locally, allowing clusters to function without relying on external networks.
- Resource Optimization: Saves bandwidth and time by eliminating the need to download images over unreliable connections repeatedly.
- Enhanced Stability: Reduces the risk of restart failures due to unavailable images, especially crucial in environments with intermittent connectivity.
Note: As of OpenShift 4.16 and 4.17, the PinnedImageSet feature is in Technology Preview. This means it’s available for early access and testing but may not be fully supported and could change in future releases. Users should exercise caution when using it in production environments.
3. Disconnected Updates: Ensuring Cluster Continuity
Maintaining a compact cluster’s uptime in disconnected environments is no small feat. Tools like the internal Mirror Registry and oc-mirror are invaluable, ensuring OpenShift deployments remain robust even when connectivity wanes.
Key Strategies:
- Pre-Load Critical Updates: Before deploying your cluster to a disconnected environment, preload essential container images and updates into your local Mirror registry using oc-mirror. This proactive approach ensures that your cluster stays operational, even if internet access becomes unavailable.
- Scheduled Synchronizations: Automate periodic synchronization tasks to update your local Mirror instance whenever network connectivity is restored. This strategy minimizes manual intervention and ensures your cluster always runs the latest software, enhancing both security and performance.
4. Avoiding Common Pitfalls in OpenShift Compact Clusters
While compact clusters offer significant advantages, their shared-resource architecture introduces unique challenges. Proper management is crucial to prevent performance degradation or system failures.
Challenges to Watch:
- Resource Contention: Imagine a single kitchen handling both gourmet meals and fast food orders—overwhelmed and inefficient. Similarly, running too many resource-intensive workloads alongside control plane services can destabilize your cluster. Prioritize control plane services by allocating adequate resources and avoiding memory-heavy applications that could cause contention.
- Plan for Growth: Compact clusters are optimized for efficiency, but growth is inevitable. Regularly monitor resource usage, anticipate future workload demands, and audit cluster performance to prevent capacity issues. Planning ahead ensures your cluster remains robust as your application portfolio expands.
5. Conclusion
OpenShift compact clusters are a beacon of efficiency and reliability for deployments in remote, resource-constrained, or disconnected environments. By leveraging tools like the internal Mirror Registry, oc-mirror, and the PinnedImageSet custom resource, and by adhering to best practices in resource management, you can ensure your deployments remain resilient and high-performing, regardless of external challenges.
Call to Action
Have you explored deploying OpenShift in a compact cluster setup? Share your experiences! What strategies propelled your success, and what obstacles did you overcome? Let’s collaborate and explore how compact clusters are transforming the landscape of edge computing and beyond.
Additional Resources
Image Pinning Enhancement Proposal
OpenShift Compact Cluster Documentation